
Unsupervised LLM Routing: Matching Oracle Performance Without Labels
How we built the Neurometric orchestration tool.

Everyone building AI-powered products eventually hits the same wall: you have a dozen models to choose from, multiple inference strategies, different evaluation judges—and no reliable way to know which combination is best for a given query. The conventional wisdom says you need labeled training data to solve this. We just proved you don’t.
We ran an experiment across 240 CRM queries spanning 8 distinct task types, 13 LLMs, 3 inference methods (chain-of-thought, ensemble-weighted, and best-of-N), and 2 judges. The question was simple: can unsupervised clustering route queries to the optimal model-method-judge system, matching an oracle that already knows the task categories?
The answer is yes. And it doesn’t even need much data to get there.
The Setup
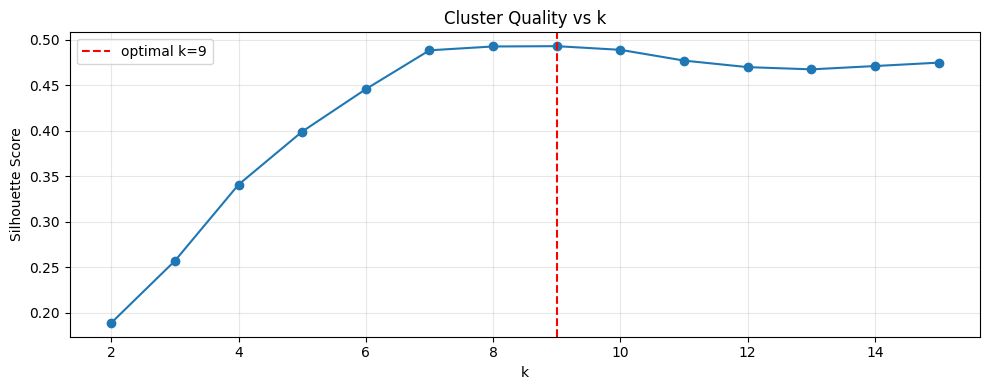
Our approach was deliberately minimal. We embedded all 240 queries using all-MiniLM-L6-v2—a lightweight sentence transformer, nothing exotic—then ran K-means clustering with k swept from 2 to 25. We selected k using silhouette score alone. No labels. No advance knowledge of how many task types existed. No human annotation of any kind.
Once clusters formed, we assigned the best-performing (model, method, judge) triple to each cluster based on per-judge consistency scores drawn from historical evaluation runs. That’s the entire pipeline: embed, cluster, assign, route.
What the Numbers Show
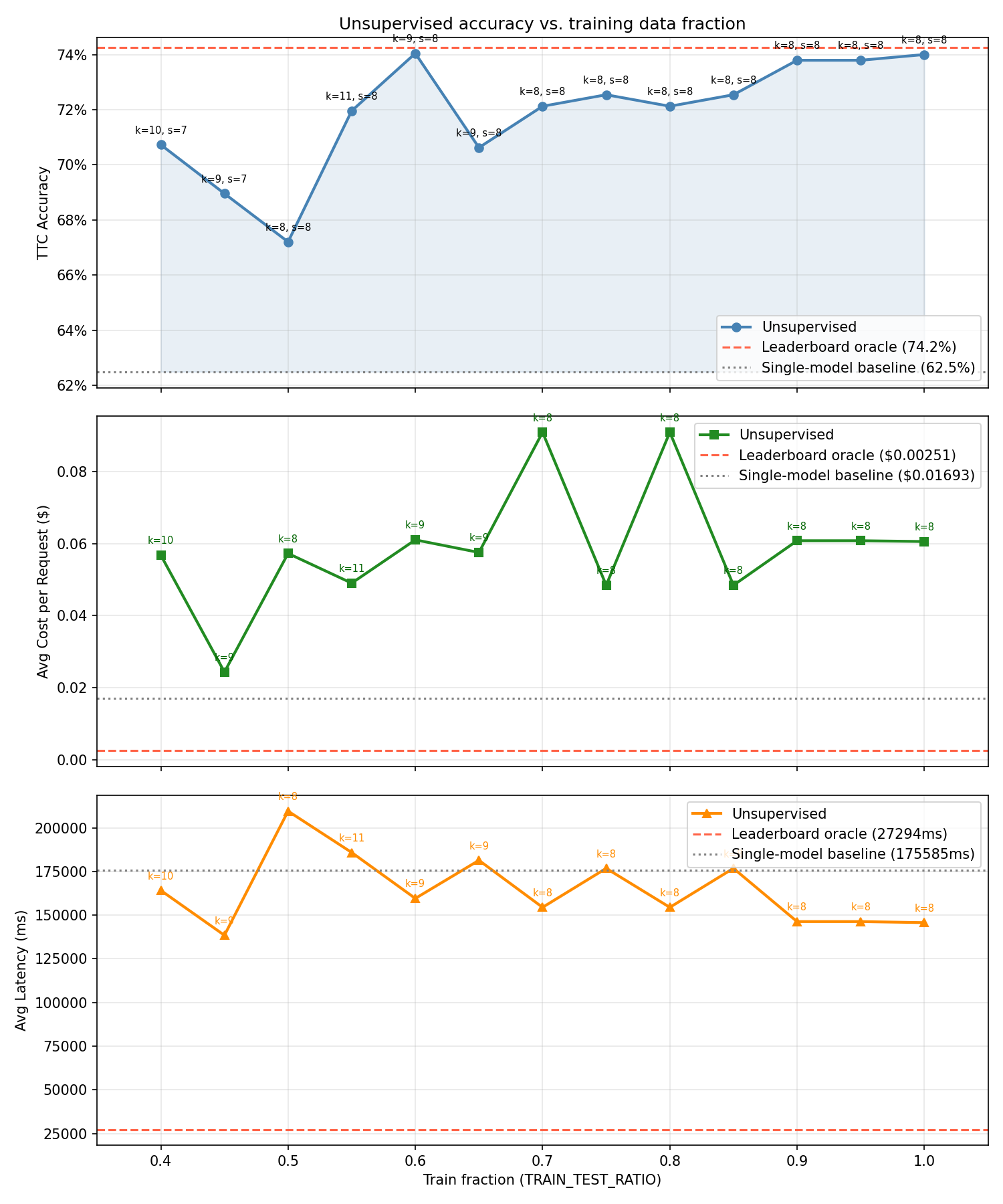
We swept the fraction of queries used for clustering—the train ratio—against the ceiling set by a fully label-aware oracle. The single-model baseline, where every query goes to the same best-on-average model, sits at 62.5%. The oracle, which knows exactly which task type each query belongs to and routes accordingly, reaches 74.2%.
Here’s where it gets interesting. At a train ratio of just 0.6—meaning only 144 of 240 queries were used to build the clusters—the unsupervised router hit 74.0% accuracy. That’s within 0.2 percentage points of the oracle. Using 100% of the data also produces 74.0%, which tells you something important: the performance ceiling isn’t about volume.
The full sweep reveals a non-monotonic pattern. At 0.4 (96 queries), accuracy is 70.7%. It dips to 67.2% at 0.5, then jumps to 74.0% at 0.6, where it essentially plateaus. Ratios of 0.7 and 0.8 both produce 72.1%. The 0.9 and 0.95 ratios land at 73.8% before returning to 74.0% at full data.
What matters isn’t having more data—it’s having a representative sample. At 60% coverage, the sample captures enough of the query distribution to define clean routing boundaries. More data after that point adds noise as often as it adds signal.
The Clusters Found the Tasks on Their Own
This is the result that surprised us most. The silhouette score search consistently selected k=8, which happens to be the exact number of actual CRM task types in the dataset. We never told the algorithm how many task types existed. It figured it out from the geometry of the embedding space.
Even more striking: 99% of queries within each cluster belonged to the same ground-truth task type. The task concordance metric across our sweep tells the story—it hits 100% at most train ratios, only dipping to 97.5-97.7% at the few ratios where k drifts to 9, 10, or 11. When the algorithm slightly over-segments, it’s splitting a task type into two related sub-clusters, not mixing unrelated tasks together.
In other words, a generic sentence embedding model—not fine-tuned on CRM data, not trained on task labels—produces a representation space where CRM query types naturally separate into distinct, tight clusters. The task structure is already in the embeddings. You just have to look for it.
What This Means for Production Routing
The practical implications are significant. Building a labeled routing dataset is expensive and slow. You need domain experts to categorize queries, you need enough examples per category to be statistically meaningful, and you need to redo the work every time your query distribution shifts. The unsupervised approach eliminates all of that.
The cost profile is also worth noting. Across our sweep, per-query routing costs ranged from roughly $0.02 to $0.09, with the best-performing configurations clustering around $0.06. Latency averaged 145-210 seconds across all model-method-judge combinations (these are full evaluation runs, not production latencies). The point is that the routing layer itself adds negligible overhead—the embedding and clustering step is computationally trivial compared to the inference calls it’s optimizing.
There’s also a cold-start story here. With labeled routing, you can’t route intelligently until you’ve built your labeled dataset. With unsupervised routing, you can start clustering from day one, refine as your query volume grows, and reach oracle-equivalent performance with a remarkably small sample. Our results suggest that 144 representative queries is enough to match what perfect task knowledge provides.
In Summary
The AI infrastructure conversation is still largely fixated on model selection—which model is “best” for a given use case. But the real leverage is in routing: dynamically matching each query to the right model, the right inference strategy, and the right evaluation judge. That’s a combinatorial optimization problem, and it turns out the query itself contains enough information to solve it without any human labeling.
This experiment used CRM queries, but the principle generalizes. Any domain where query types have distinct semantic signatures—customer support, legal analysis, code generation, medical triage—should exhibit the same clustering behavior. The embedding space encodes task structure whether you ask for it or not.
The takeaway is straightforward: unsupervised clustering on query embeddings matches a label-aware oracle using just 60% of available queries. If you’re building multi-model infrastructure and waiting until you have a labeled routing dataset to start optimizing, you’re leaving performance on the table. The labels you think you need are already implicit in the queries themselves.