
Training A Small Language Model To Outperform Frontier Models On CRM-Arena
How We Fine Tuned a 4B Parameter Model to 95% Accuracy

Much of the research we are doing at Neurometric focuses on how to auto-generate SLMs for specific tasks. After evaluating test time compute strategies on various models and publishing our Leaderboard, we turned to SLMs. There’s a growing assumption in the AI world that bigger is always better. More parameters, more compute, more everything. But what if a model with fewer than 6 billion parameters could hold its own against models 10x or 20x its size on real enterprise tasks?
The Setup: CRMArena as Our Proving Ground
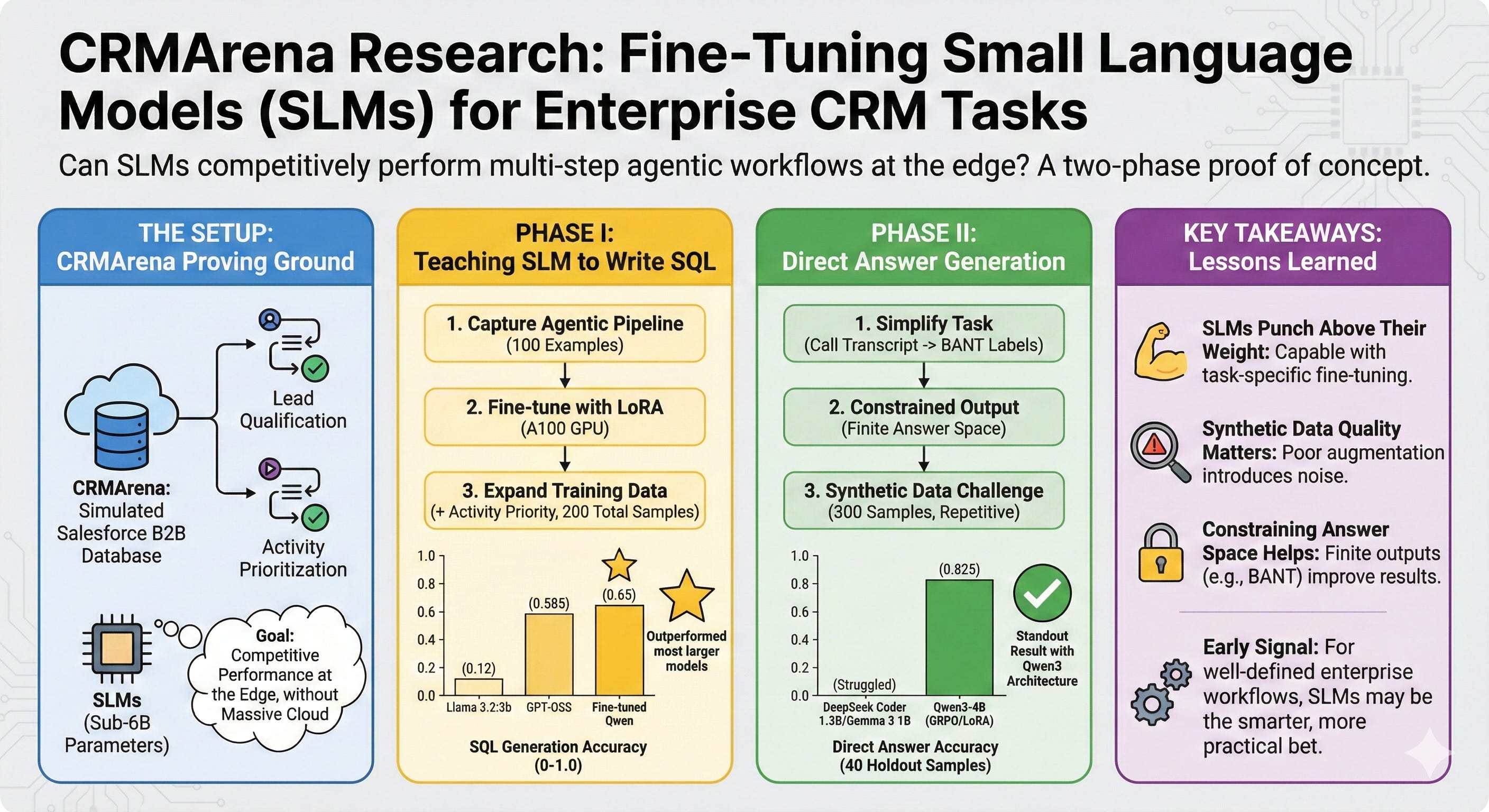
CRMArena is a benchmark built around realistic Salesforce CRM tasks. Think lead qualification, activity prioritization — the kind of work that sales ops teams grind through every day. It uses a simulated Salesforce B2B database, and models are evaluated on how accurately they can work through multi-step agentic workflows to arrive at correct answers.
We wanted to know: could we fine-tune a small language model (SLM) to perform these tasks competitively? Not as a toy experiment, but as a genuine proof point for running capable AI at the edge, where massive cloud-hosted models aren’t always practical.
Phase I: Teaching a Small Model to Write SQL
Our first attempt focused on one specific piece of the puzzle — generating the SQL queries that pull the right data from Salesforce. We simulated the full agentic pipeline across all 100 examples in the CRMArena database, capturing the conversation flows that lead to valid SQL output. Then we used that data to fine-tune several sub-6B parameter models using LoRA adapters on an A100 GPU.
The early results were rough. The models struggled to capture the underlying reasoning of the agentic workflow. Instead of learning what to generate, they tried to replicate the entire message exchange — producing incoherent, off-target output.
But things improved when we expanded the training data. Adding SQL examples from a second task (Activity Priority) alongside Lead Qualification — even with only 200 total training samples — led to a noticeable jump in valid query generation.
Here’s where it got interesting. When we plugged our best fine-tuned Qwen model back into the full agentic pipeline for Lead Qualification, it scored 0.65. For context, non-fine-tuned models on the same test set ranged from 0.12 (Llama 3.2:3b) to 0.585 (GPT-OSS). Our fine-tuned SLM outperformed all but two of the larger, general-purpose models — and beat its own base Qwen variant by 20 points.
Phase II: Going Straight to the Answer
Encouraged by Phase I, we shifted strategy. Instead of generating SQL, what if the model could skip straight to the final answer?
For Lead Qualification, the answer space is finite: any combination of Budget, Authority, Need, and Timeline (the BANT framework), or “None.” That constrained output made it a strong candidate for direct answer generation.
We stripped out the verbose database schema instructions and replaced them with a concise task description. The model’s job was simple: read the call transcript data and return the correct BANT labels.
We also tackled the data scarcity problem. With only 100 original examples, we used GPT to generate 300 additional synthetic training samples. In hindsight, these synthetic examples were overly repetitive and didn’t faithfully represent the original task — a lesson in the importance of data quality over quantity.
Despite that limitation, training with GRPO and LoRA produced a standout result. The Qwen3-4B model achieved an evaluation score of 0.825 on 40 holdout samples. Other models (DeepSeek Coder 1.3B, Gemma 3 1B) struggled — some tried generating narrative responses, others hallucinated more SQL queries — but the Qwen3 architecture seemed particularly well-suited to constrained answer generation.
What We Took Away
Three things stood out from this work. First, small models can punch well above their weight when fine-tuned on task-specific data — even with very limited training samples. Second, synthetic data generation is a double-edged sword; it can expand your dataset, but poor-quality augmentation introduces noise that’s hard to detect without rigorous validation. Third, constraining the answer space matters. The finite set of BANT labels almost certainly contributed to the strong Phase II results, and it remains an open question whether this approach generalizes to tasks with more open-ended outputs.
We’re continuing to explore these questions across additional CRMArena tasks. But the early signal is clear: for well-defined enterprise workflows, small language models aren’t just viable — they may be the smarter bet.