
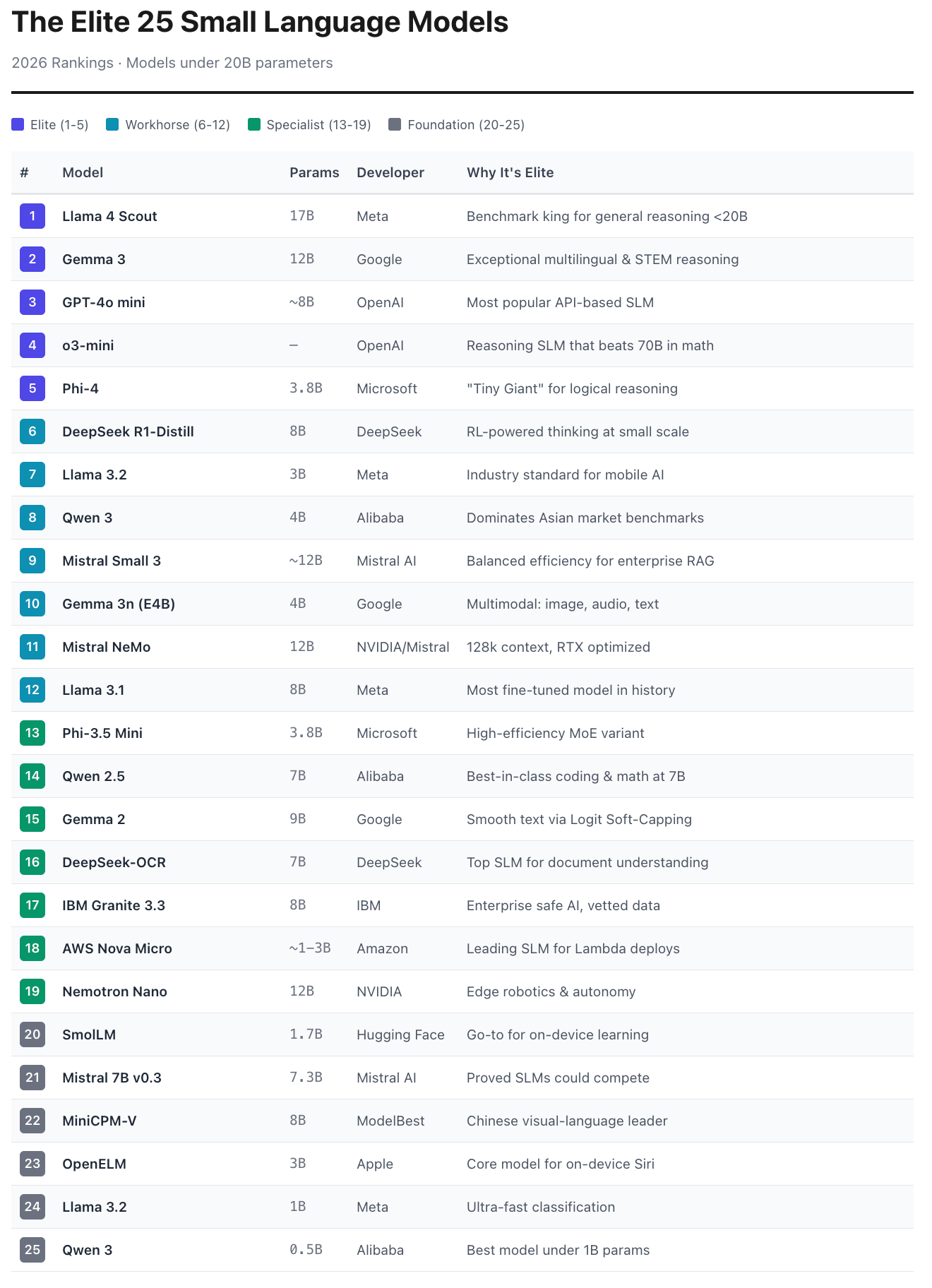
The Top 25 Small Language Models
The future of AI isn’t just bigger—it’s smaller, faster, and everywhere.

At Neurometric, we are focused on optimizing inference using small language models for specific tasks. This maps better to agentic use cases and edge workflows. That’s a change from the conventional AI wisdom.
For the past three years, the AI narrative has been dominated by a single storyline: make the models bigger. GPT-4 reportedly has over a trillion parameters. Claude and Gemini have followed similar trajectories. The assumption was simple—more parameters meant more intelligence, and more intelligence meant more value.
That assumption is now being dismantled, one small language model at a time.
Welcome to 2026, where a 4-billion parameter model can outperform last year’s 70-billion parameter giant on specific tasks. Where enterprises are discovering that the $0.15 per million token API call delivers 90% of the value at 5% of the cost. Where the phone in your pocket runs sophisticated AI without ever pinging a server.
Small Language Models (SLMs) have graduated from “interesting research direction” to “default deployment choice” for an enormous range of applications. And if you’re building, investing, or just trying to understand where AI is heading, you need to know which ones matter.
Here’s my definitive ranking of the 25 most important Small Language Models in production today.
A Complete Ranking
What Defines “Small”?
Before diving deeper, let’s establish what we mean by “small.” In this analysis, I’m using a 20-billion parameter ceiling. This isn’t arbitrary—it represents roughly the threshold below which models can run efficiently on consumer-grade GPUs (like an RTX 4090), on-device mobile processors, or cost-effectively at massive API scale.
This matters because it’s the boundary between “we need dedicated infrastructure” and “we can deploy this almost anywhere.” Below 20B parameters, you enter a world where inference costs drop by 80-90%, latency shrinks to milliseconds, and the economics of AI fundamentally change.
The Championship Tier: Models 1-5
The top five models on this list aren’t just incrementally better—they represent genuine breakthroughs in what’s possible at small scale.
Llama 4 Scout takes the crown not because of any single capability, but because of its remarkable consistency. Meta’s latest small model achieves GPT-4-level performance on standard reasoning benchmarks while maintaining the open-weights philosophy that makes it infinitely customizable. For enterprises building proprietary AI systems, Scout has become the starting point for nearly every serious project.
Gemma 3 from Google deserves its silver medal for dominating the multilingual and STEM categories. If your application involves multiple languages or technical reasoning—and increasingly, enterprise applications involve both—Gemma 3 is often the right choice. Google’s training methodology has produced a model that “thinks” in a notably different way than the Llama family, which makes it particularly valuable for ensemble approaches.
The bronze goes to GPT-4o mini, which might be the most commercially significant model on this list. OpenAI’s decision to release a small, cheap, fast variant of their flagship model has made sophisticated AI accessible to applications that could never justify the cost of GPT-4. I estimate it handles more daily API calls than any other model in existence. It’s not the smartest small model, but it might be the most important one.
o3-mini represents something genuinely new: a reasoning-specialized small model that employs chain-of-thought processing to beat models five to ten times its size on mathematical and logical tasks. OpenAI hasn’t disclosed its exact parameter count, but whatever the number, this model proves that architecture and training methodology can matter more than raw scale.
Rounding out the elite tier is Microsoft’s Phi-4, the model I privately call “the Tiny Giant.” At just 3.8 billion parameters, Phi-4 shouldn’t be able to compete with 12B or 17B models. Yet on instruction-following and logical reasoning, it does exactly that. Microsoft’s approach—training on extremely high-quality synthetic data—has produced a model that punches dramatically above its weight class. For developers who need maximum capability in minimum footprint, Phi-4 is often the answer.
The Workhorses: Models 6-12
This tier contains the models that enterprises actually deploy at scale every day.
DeepSeek R1-Distill-Llama brings reinforcement learning techniques to small models, creating a model that genuinely “thinks through” problems rather than pattern-matching to solutions. DeepSeek has been quietly producing some of the most innovative open models, and this distillation of their R1 architecture into an 8B package is remarkable.
Llama 3.2 at 3B has become synonymous with mobile AI. When you use an on-device AI feature on an Android phone or an Apple device running third-party apps, there’s a good chance you’re interacting with this model or a fine-tuned derivative. Meta’s optimization work with Qualcomm and Apple Silicon has made it the default choice for on-device deployment.
Qwen 3 (the 4B variant) dominates the Asian market in ways that Western observers often underestimate. Alibaba has built a model that excels specifically at Chinese, Japanese, and Korean language tasks, while remaining competitive on English benchmarks. For any business with Asian market exposure, Qwen should be on the radar.
Mistral Small 3 and Mistral NeMo represent the French AI company’s continued excellence in the enterprise segment. Mistral Small 3 has found its niche in RAG (Retrieval-Augmented Generation) workflows where its balance of speed and accuracy makes it ideal for searching and synthesizing large document collections. NeMo’s 128k context window—enormous for a model this size—makes it the choice for applications requiring extensive context.
Gemma 3n deserves special attention as a multimodal SLM. This 4-billion parameter model handles images, audio, and text natively—not through bolted-on adapters, but through genuine multimodal training. For edge devices that need to process multiple input types, Gemma 3n is increasingly the first choice.
Llama 3.1 at 8B might be the most fine-tuned model in history. It’s not the newest or the most capable, but the sheer volume of specialized variants available—for code, for medical text, for legal documents, for creative writing—makes it invaluable. When you need a specialized small model, chances are someone has already fine-tuned Llama 3.1 8B for your use case.
The Specialists: Models 13-19
This tier showcases models optimized for specific use cases rather than general capability.
Phi-3.5 Mini brings Mixture-of-Experts architecture to the small model space, allowing it to maintain broad capability while staying within a tiny footprint. Qwen 2.5 has become the default choice for code generation in the 7B range, consistently outperforming larger models on programming benchmarks. Gemma 2 remains popular for its notably smooth, natural text generation.
DeepSeek-OCR represents the growing importance of document AI. As enterprises digitize paper processes, the ability to understand documents—not just read them, but genuinely comprehend their structure and meaning—becomes critical. This 7B model currently leads the SLM category for document intelligence.
IBM Granite 3.3 addresses a specific enterprise concern: AI governance. Trained exclusively on data IBM can legally and ethically vouch for, Granite appeals to regulated industries that need to demonstrate their AI’s provenance. It’s not the most capable model, but for some buyers, its “cleanroom” training is worth the capability tradeoff.
AWS Nova Micro and NVIDIA Nemotron Nano represent hardware-ecosystem plays. Nova Micro runs exceptionally well within AWS infrastructure, making it the default for Lambda-based AI applications. Nemotron Nano is specifically optimized for NVIDIA’s Jetson platform, targeting robotics and autonomous systems. Both demonstrate that small models increasingly need to be understood not just by their capabilities, but by their deployment targets.
The Foundation Layer: Models 20-25
The final tier contains models that, while less capable in absolute terms, fill crucial niches in the ecosystem.
SmolLM from Hugging Face has become the default starting point for developers learning to work with on-device AI. Its simplicity and extensive documentation make it invaluable for education and prototyping.
Mistral 7B v0.3 deserves recognition as the model that proved the SLM thesis. When it launched in 2023, it demonstrated that small models could genuinely compete with models ten times their size. Much of what followed built on its success.
MiniCPM-V and OpenELM represent the visual-language and on-device categories respectively. MiniCPM-V dominates mobile visual AI in China, while Apple’s OpenELM powers an increasing number of on-device features in iOS.
The final two entries—Llama 3.2 at 1B and Qwen 3 at 0.5B—represent the extreme efficiency frontier. These models can run on almost any device, handle basic text tasks with minimal latency, and cost essentially nothing to operate. They’re not sophisticated, but they don’t need to be. For simple classification, summarization, and text processing, they’re often exactly right.
What It Means For Builders
What does this landscape mean for builders?
First, the SLM space is exploding. More importantly, the open-source models are winning the deployment war even as closed models win the capability war.
Second, specialization is the path to value. Generic small models are becoming commoditized. The models that command premium positioning—and premium pricing—are those optimized for specific use cases: document understanding, code generation, on-device deployment, enterprise compliance.
Third, the infrastructure layer matters enormously. Models optimized for specific hardware (NVIDIA, AWS, Qualcomm, Apple Silicon) create ecosystem lock-in that pure capability cannot.
Finally, the economics favor orchestration. No single small model excels at everything. The winning architecture involves routing different tasks to different specialized models—exactly the thesis behind Neurometric’s intelligent small model orchestration.
We’re entering an era where AI capability becomes a commodity and AI deployment becomes the competitive battleground. Small Language Models aren’t a compromise—they’re the future of how AI actually gets used in the real world.
The models on this list represent the state of the art in efficient, deployable, practical AI. If you’re building applications, these are your building blocks. The giants made AI possible. The small models are making it practical.
If you want to use small models at your company, contact us for a demo.
Qwen has moved fast since this list went out. The 3.5 release dropped with a 4B and 9B that genuinely trade blows with models two to three times their size. The 4B especially is punching well above its weight class for local inference. Surprised it isn't getting more attention. Wrote up the full breakdown with benchmarks and how to get it running: https://reading.sh/your-laptop-is-an-ai-server-now-370bad238461?sk=1cf7a4391e614720ecbd6e9bc3f076a2
This list is useful but the real question is: which SLM for which task? I ran experiments across Claude's model range—Haiku crushes structured tasks, email, code execution. Opus only wins on multi-step reasoning.
The benchmark that matters isn't aggregate scores. It's task-specific performance vs cost. Some of these smaller models beat larger ones on narrow domains while costing 15x less.