
New Feature Launch: Addressing The Eval Problem With Cosine Similarity
Relative model evals for customers that don't have good eval sets

One of the biggest surprises we’ve seen at Neurometric is that most people don’t have evals. They just use one of the top frontier models and assume that’s the best they can do. So for example, lets say you have thousands of pages of industry reports and you want to feed it to a model and pull out all the stock symbols in those reports. In use cases like that, companies often don’t have eval sets they just assume using the best model gives a fine result.
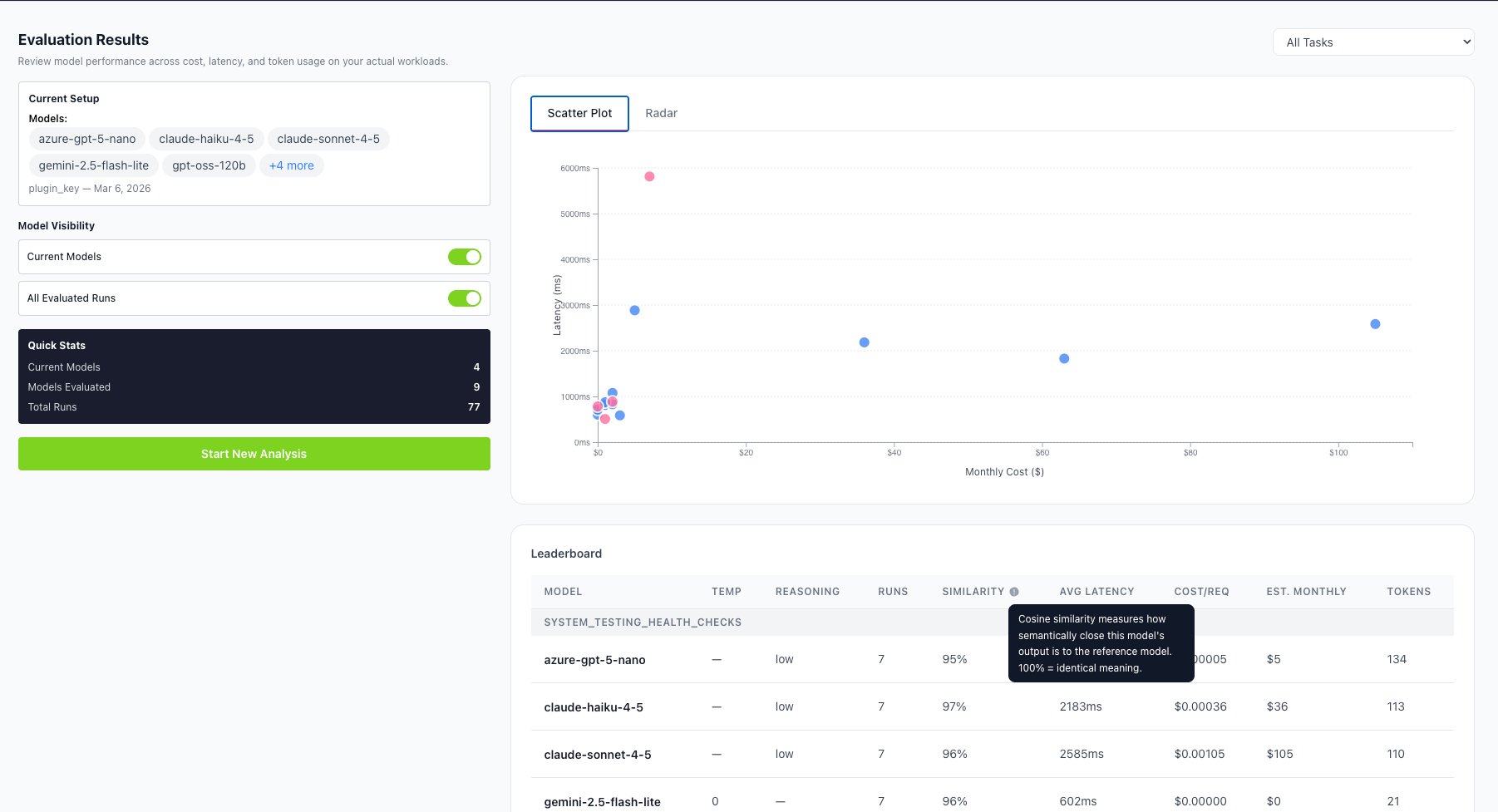
For Neurometric, that means model evaluation is difficult. If we find a model that is much faster and much cheaper at the same task, how do we know if the quality is the same? Our approach is to use relative evals. We recently added functionality, which you can see in the screenshot above, that uses cosine similarity to compare those outputs.
When models convert language into vectors, cosine similiarity is a mathematical technique to measure the similarity between two vectors. For text based model responses, this translates into how similar the responses are. Now when you want to optimize your system but don’t have good evals, we have a process that still helps you make good decisions.
Inference optimization is increasingly important, as recent use cases like AT&T’s 90% reduction in token costs show. Neurometric can make your system 5x faster and 10x cheaper, and now we can do it even if you don’t have great evals. Reach out if you think we can help, or try out the Neurometric Studio for free here.