
Introducing The Neurometric Token Engineering Platform
optimize your inference system

When we started Neurometric we spoke to many large enterprises about what they were doing with AI and how they were building out their systems. Most were not very far along but the few that were had all independently come to the same architecture.
They all started with one large frontier model, and as their inference costs grew, they started to peel off their high volume simpler workloads and set up “task specific endpoints.” Workloads like customer sentiment analysis of support tickets, named entity extraction from documents, email summarization, these don’t need frontier intelligence. By setting up an endpoint with a small model for just those workflows, they saw lower costs and faster latency.
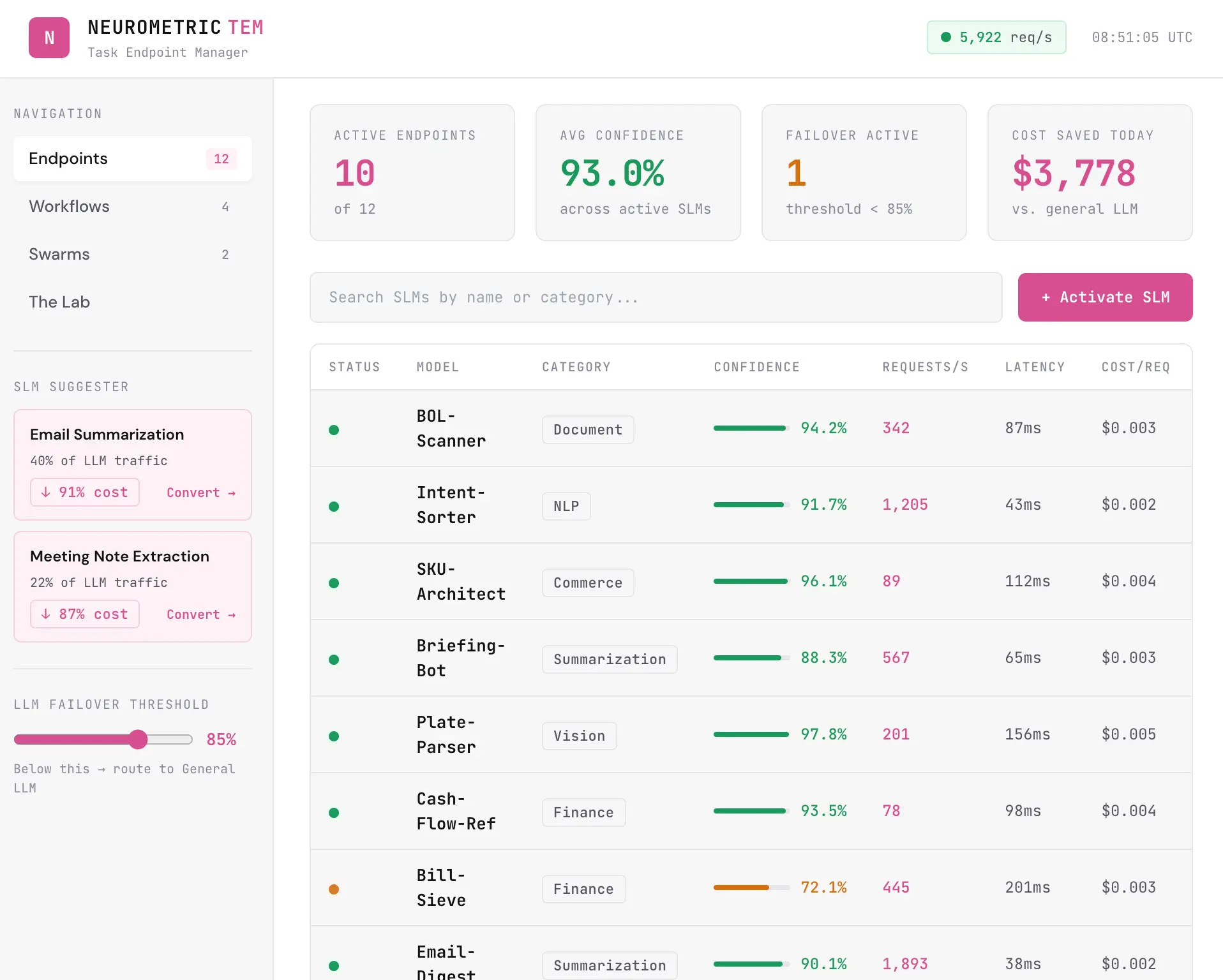
The problem is, there are thousands of models out there, and hundreds of techniques to optimize them - from where you run the model to prompting and token management techniques. And that is all on top of the complicated issue of which model works best for your use case in the first place.
Today we are announcing that Neurometric has pulled all of these tools together in a single platform that makes it easy to make token engineering decisions. With our platform you can:
Monitor and measure AI workloads
Optimize workloads for cost or latency
Build custom SLMs for workloads that benefit from that approach
Evaluate and test many models, techniques, and hosting platforms
Our customers typically see an 80% drop in inference charges and a 4x improvement in latency using the Neurometric platform.
If you want take your AI optimization to the next level, hire a token engineer, and use the Neurometric platform. Reach out to us at sales@neurometric.ai if you want to learn more.